
How to Use the SPIglass™ Dashboard
Overview
The SPIglass™ Dashboard is the executive-level reporting interface within the Spirion Sensitive Data Platform. While the Scans Dashboard focuses on operational management, SPIglass is designed to provide a high-level view of an organization's overall risk posture and ROI.
What does the SPIglass™ Dashboard do?
The SPIglass™ Dashboard translates raw scan data into financial and risk-based metrics using the following key components:
- Risk Quantification: It calculates the "Total Potential Risk (Cost)" by multiplying the number of sensitive data findings by the estimated cost of a data breach (often based on industry standards like the Ponemon Institute report).
- Comparison Metrics: It features data cards that show percentage changes in risk over time (e.g., Compensating Controls and Remediated Risk). These are updated on a weekly basis (Sunday to Sunday).
- Visual Analytics: It provides several charts to help identify "hot spots" of sensitive data:
- Risk by Location: Shows which storage areas (SharePoint, File Servers, etc.) hold the most risk.
- Risk by Classification: Breaks down risk by data type (e.g., PII, PHI, PCI).
- Data Age: Identifies how much sensitive data is "stale" or hasn't been modified in years.
- Executive Reporting: It is designed to be shared with CISOs and stakeholders to demonstrate the value of data cleanup and remediation efforts. Findings of interest can be presented to board members or executives such as current and future sensitive data security plans as well as the current amount and value of sensitive data which is protected or exposed.
The dashboard highlights Key metrics:
- The Alert Pink color is used to highlight high risk areas, at-risk sensitive data types and data repositories, company departments with the most at-risk data, and the cost of exposed sensitive data. archTIS recommends you focus on the data highlighted in Alert Pink first and foremost.
Each chart depicts a high-level roll up of data that reveals insights into your sensitive, personal, and private data, and where to focus when managing this data as well as the risk it poses to your organization.
Dashboard Refresh Interval
The SPIglass™ dashboard doesn’t refresh in real time—it updates on a scheduled ingestion cycle.
- After each scan, data caches to the "CachedDashboardCharts" table
- The dashboard is updated by Service Task Type 10, which is managed by the
TasksSchedulerservice. - Frequency: This task is typically scheduled to run once per day.
- Timing: In most production environments, it is configured to run during off-peak hours (overnight) to avoid the performance impact of recalculating massive datasets (like the Data Footprint or Inherent Risk charts) during the workday.
However, there is an "Event-Based Refresh (The "Automatic" Trigger)." While it has a daily schedule, certain system events are designed to trigger a refresh of the cache more frequently:
- After a Scan Job: The dashboard data refreshes automatically after a job run completes. However, in some environments, this automatic trigger may fail due to the amount of data, leaving the data "stale" until the next daily scheduled run or manual intervention.
Compensating Controls

Compensating Controls: Displays the total cost of all sensitive data matches with compensating controls in place.
"Compensating Controls" include any of the following actions applied to sensitive data by Spirion Sensitive Data Platform:
- Restricted Access
- Script Execution
- Quarantine
- Ignore (sensitive data match ignored or sensitive data location ignored)
Note: All costs are taken from the dollar value assigned to each data type in the global data types settings in the Data Asset Inventory. See Working with Data Asset Inventory for more information.
PW Indicator
- The arrow and number percent % indicates the direction (increase or decrease) and change (in percent %) over the past week (PW)
- In the screenshot above, the total cost of all amount of all sensitive data matches with compensating controls in place has increased 2% in the past week.
Remediated Risk

Remediated Risk: Displays the total cost of all sensitive data matches that have been found and subsequently removed using Spirion Sensitive Data Platform via the shred or redact action.
- Data Type:
- Dollar Value (Default $8.00)
- Leverage Playbook Actions:
- Shred
- Redact
Note: All costs are taken from the dollar value assigned to each data type in the global data types settings in the Data Asset Inventory. See How to Get Started with Data Asset Inventory for more information.
PW Indicator
- The arrow and number percent % indicates the direction (increase or decrease) and change (in percent %) over the past week (PW)
- In the Remediated Risk screenshot above, the total cost of the amount of all sensitive data matches with compensating controls in place has increased less than 1% in the past week.
Organizational Data Risk
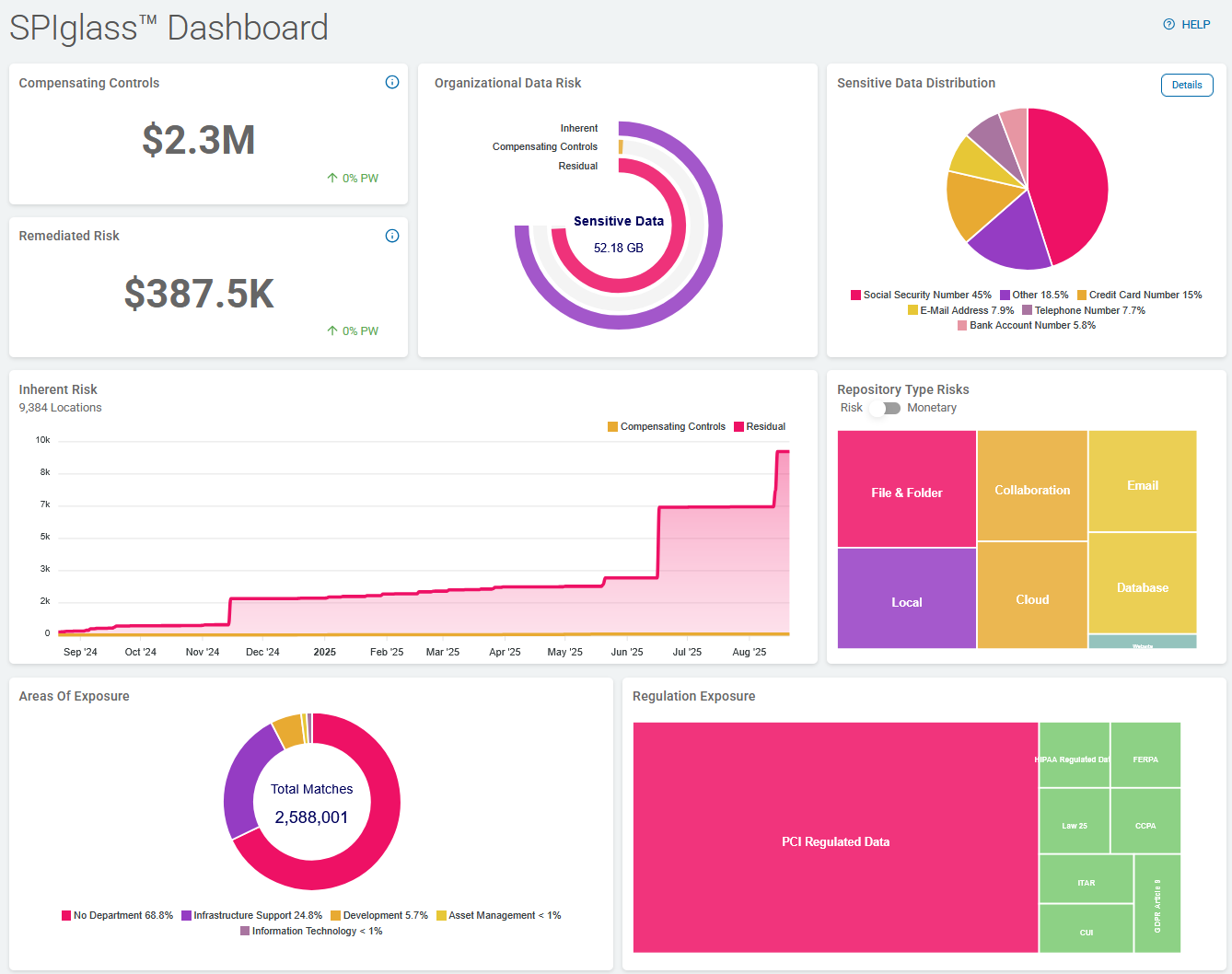
Organizational Data Risk displays all the scanned data in your environment.
The data is displayed by:
- Inherent: Represents all sensitive data identified
- Displayed in the purple-colored, outermost line
- The Inherent line is the sum of the Compensating Controls line and the Residual line.
- Amount of sensitive data (volume) is displayed in the center of the circle labeled Sensitive Data (43.80 GB in the screenshot above)
- Compensating Controls: Data that has some form of protection or remediation in place (Managed Data in Spirion Sensitive Data Platform).
- Displayed in the amber-colored, middle line.
- Managed data represents the sensitive data that has been addressed with one of the following actions:
- Restrict Access
- Script
- Quarantine
- Ignore
- User Action
- Residual: Displays deleted data in your environment that is exposed (at-risk).
- Displayed in the Alert Pink colored portion of the innermost line
- This is specifically matched data that is still in your environment and has not been managed to reduce accessibility or remediated.
Note: The total of Compensating Controls data and Residual data is equivalent to the total Sensitive data, but is likely not equivalent to the total Scanned data.
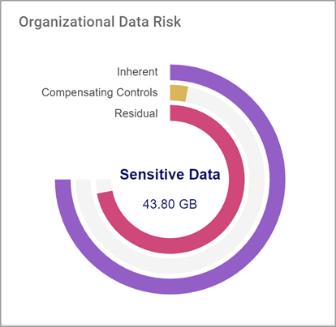
Optimum vs. Problematic Organizational Data Risk
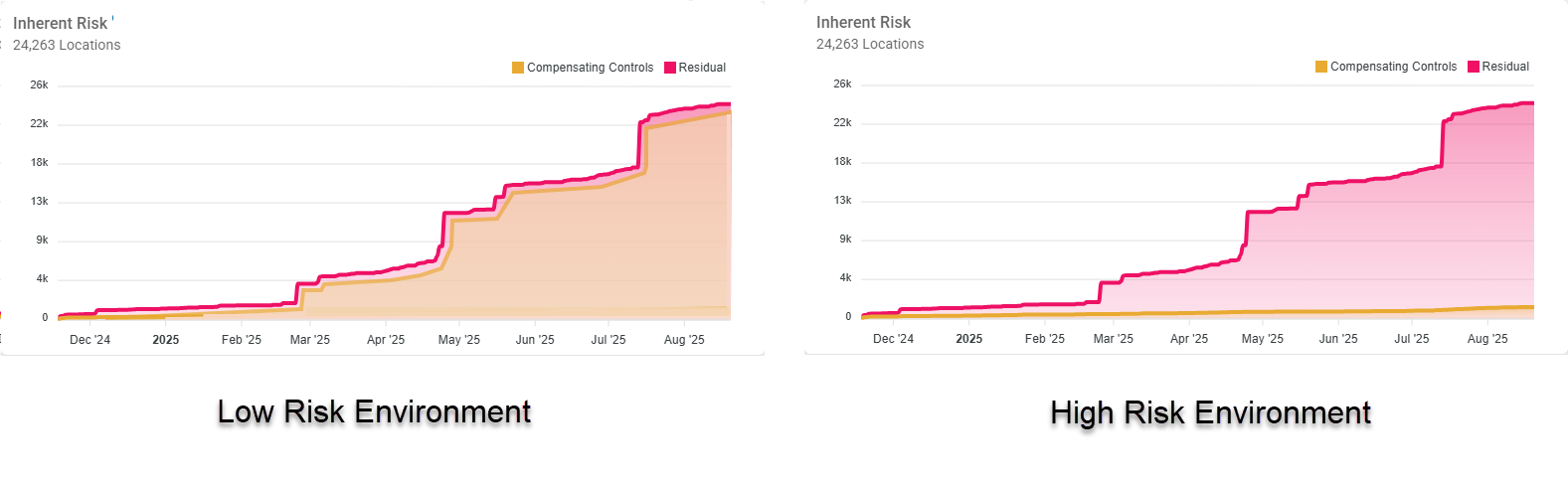
Below is an example of low organizational data risk vs. high organizational data risk as displayed by the Organizational Data Risk circle graph.
Organizational Data Risk Graphs - Examples of Low versus High Data Risk
- Organizational Data Risk is:
- Low when Compensating Controls, shown in the amber middle line in the semi-circle chart, is much longer than the Residual line, shown in Alert Pink on the inside.
- High (and requires action) when Compensating Controls, shown in the amber middle line in the semi-circle chart, is much shorter than the Residual line, shown in Alert Pink on the inside.
- Recall, the Inherent line (purple line in the graph above) represents all identified sensitive data and is the sum of the Compensating Controls semi-circle line and the Residual semi-circle line.
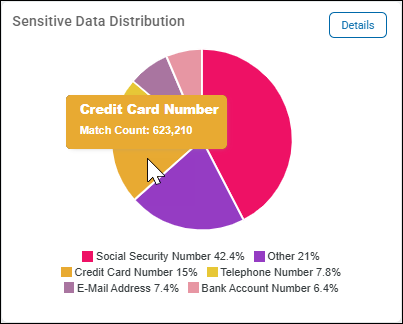
Sensitive Data Distribution
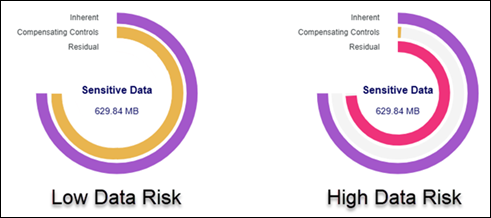
Sensitive Data Distribution is a pie chart that displays the following information:
- The 5 most discovered sensitive data types, such as Social Security numbers, Credit Card numbers, E-mail Addresses, Date of Birth, Telephone Numbers, etc.
- All other data type matches are shown as Other.
- Alert Pink color is used to highlight the largest amount of at-risk data (Social Security Numbers in the pie chart example shown here)
- Mouse over a section in the pie chart to view exact match count for the sensitive data type.
- In the screenshot below, the Match Count of Credit Card Numbers is 623,210.
- This means Sensitive Data scans have discovered 623,210 individual credit card numbers. These numbers are not unique. In this example credit card numbers account for 15% of all sensitive data matches in the scanned environment.
- Social Security numbers account for 42.4% of all sensitive data matches here, and while they represent the most valuable type of sensitive data in the environment, credit card numbers are the 3rd most type of sensitive data and must be monitored.
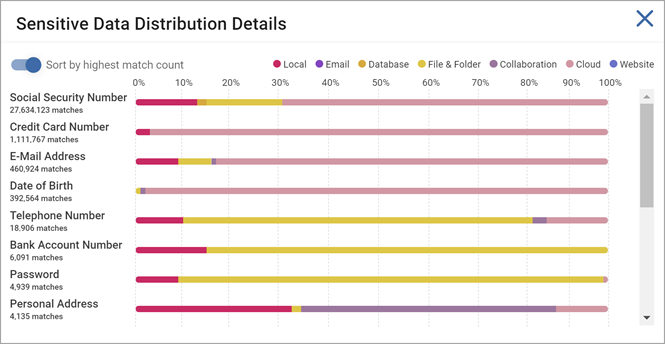
Sensitive Data Distribution Details
- Click the Details button in the top right corner of the "Sensitive Data Distribution" tile to view the distribution of sensitive data across all repository types, listed here:
- Local - Local file servers or the files and folders on local workstations, laptops, desktops, etc.
- Email - Exchange, Exchange Online, Gmail
- Database - Oracle, PostgreSQL, Snowflake, etc.
- File & Folder - Remote file servers or the files and folders on remote workstations, laptops, desktops, etc.
- Collaboration - SharePoint On-Premise, SharePoint Online, Bitbucket
- Cloud - OneDrive, Box, Dropbox, etc.
- Website - Configured websites
- The bar graph shown is a version of the Scans Dashboard Sensitive Data Distribution chart. (See Using Scans Dashboard for more information.)
- Mouse over a sensitive data type bar in the chart to see the breakdown of that data type across all repository types (Local, Email, Database, File & Folder, Collaboration, Cloud, Website).
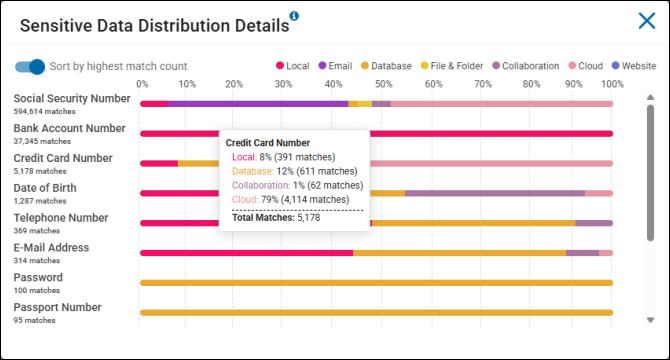
Example
- In the screenshot above, for example, Credit Card Number data types were matched a total of 5,178 times.
- The breakdown of matches by repository types is as follows:
- 8% of the 5.178 matches were found on Local sources (remote machines, file servers, workstations, etc.)
- 12% of the 5.178 matches were found on Database sources (Oracle, PostgreSQL, mongoDB, Snowflake, etc.)
- 1% of the 5.178 matches were found on Collaboration sources (SharePoint, Bitbucket)
- 79% of the 5.178 matches were found on Cloud sources (Dropbox, OneDrive, Amazon S3, etc.)
- Note: In this example no Credit Card Number matches were found on either Email or File & Folder repository type
Inherent Risk
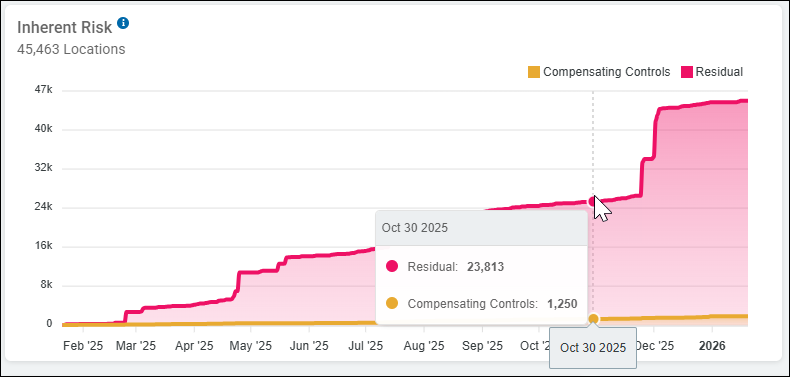
The Inherent Risk tile displays a time-aligned graph which measures the amount of low-risk data (data with Compensating Controls applied) versus high-risk data (Residual data) in your environment over time.
- This graph shows Residual data displayed using a line and shaded area in Alert Pink, on top of data with Compensating Controls applied to it, displayed with a line and shaded area in amber.
- Residual data, also known as ambient data, refers to information that remains on storage devices even after attempts to delete or erase it.
- Compensating Controls are actions applied to sensitive data discovered in your environment to mitigate risks. These actions include:
- Restricted Access: Limiting who can view or interact with the data
- Script Execution: Running scripts to manage or remediate data
- Quarantine: Isolating sensitive data to prevent unauthorized access
- Ignore: Choosing not to act on certain sensitive data matches or sensitive data locations (file, including full path to the file, or email)
- Note: Data which has received the following actions is excluded from the Inherent Risk graph: Classification, User Action, Assign, Notify, MIP Label, Shred, Redact, Take No Action
- Remediated data (data which has been shred or redacted) is filtered out as those items are no longer At Risk
- Y Axis
- Indicates the total number of locations with sensitive data
- In the screenshot above, there are a total of 45,463 locations
- A "location" is a file, including path (example: \\server1\folder), or email
- Residual data is shown on top of the data with Compensating Controls applied
- Residual data is represented in Alert Pink
- Data with Compensating Controls is represented in Amber
- X Axis
- Indicates the month of the year in which the inherent risk was at the level indicated on the Y axis.
- Mouse over a point in the graph to see details, including the date. See the screenshot above.
Environments with High vs. Low Inherent Data Risk
Below is an example of an environment with low Inherent data risk (left) vs. one with high Inherent data risk (right).
- Inherent (data) Risk is categorized as follows:
- Low risk when Compensating Controls, represented by the amber shaded portion, tracks equally with the Residual line, shaded in Alert Pink.
- High risk (and requires action) when Compensating Controls, represented by the amber shaded portion, lags below the Residual line, shaded in Alert Pink.
- The gap between the Compensating Controls line and the Residual data line should be as small as possible at all times as shown in the graph on the left in the image below.
- If your environment resembles the High Risk Environment as shown in the graph on the right in the image below, you must take action to apply compensating controls and lower the risk of your exposed sensitive data as soon as possible!
Repository Type Risks

- Repository Type Risk tile displays the SDV3™ risk score of each repository type (Cloud, Local, Email, etc.) in your environment (Asset Assignment for all Scanned Targets) in a tree map
Note: This feature requires that Data Type Values and Asset Security Measures are entered.
- The SDV3™ risk score is calculated by averaging the risk score associated with all assets within a specific repository
- Repository Types are as follows:
- Cloud
- Local (Scans)
- Database
- Files & Folders (Remote Scans)
- Website
- Collaboration Tools
- Hover over one of the following repository types to view its details:

- Repository Type Risks score is indicated by the relative square size in the tree map
- Each square is color-coded based on a set risk score threshold with the highest risk score always highlighted in Alert Pink

- Each square is color-coded based on a set risk score threshold with the highest risk score always highlighted in Alert Pink
- The Risk/Monetary toggle enables you to display the chart by monetary value, which may not correspond with the highest risk if the repository has a low vulnerability but a high value
- Monetary values are indicated in the tree map in the same manner as risk score
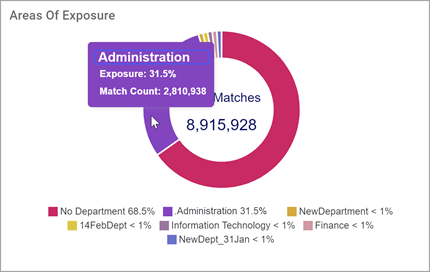
Areas of Exposure
Areas of Exposure tile displays the total sensitive data matches in each department as identified in the Data Asset Inventory (DAI).
- Each section represents a department or matches without a corresponding department
- Hover over a section to view a total match count of each department
- The total match count for the environment is displayed in the center of the chart
- The legend lists each match (as a percent % of the total) for each department
- For example: Human Resources, Sales, Engineering, etc.
- Sensitive data distribution (as a percent % of the total) by department
- Percent of each data type for Total Findings (Scan for Data Types)
- Areas of exposure for each department
- Asset department assignment in Data Asset Inventory
- Department examples: Administration, Finance, IT, Dev
- Scanned Targets assigned to assets in Data Asset Inventory
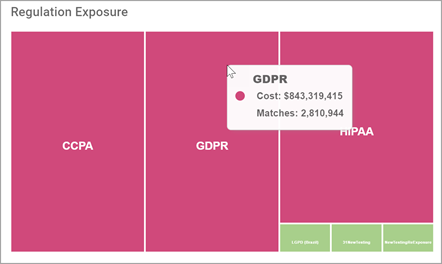
Regulation Exposure
Regulation Exposure displays the dollar value and match count of data identified in Assets with a regulation property.
- Regulation Exposure: GDPR, HIPAA, etc.
- For more about GDPR, see "GDPR Lessons Learned From 200 Companies Who Got It Wrong"
- Asset Regulation Assignment in Data Asset Inventory
- Scanned Targets Assigned to Assets in Data Asset Inventory
- The dollar value of each regulation is indicated by the size and color of the squares in the chart
- The highest Dollar value is always shown in Alert Pink
- Hover your mouse pointer over a section for more detail.
- In the example screenshot below the CCPA (California Consumer Privacy Act), GDPR (General Data Protection Regulation), and HIPAA (Health Insurance Portability and Accountability Act) blocks in the tree map are the majority of the regulation exposure and therefore are shown in Alert Pink.
- GDPR (General Data Protection Regulation) has been moused over and displays the total dollar value ($843,319,415) of all of the captured sensitive data matches (2,810,944) associated with that regulation
Note: For Regulation Exposure to be accurate, you must set up Assets in your Data Asset Inventory (DAI) and include relevant regulations. See How to Get Started with Data Asset Inventory for more information.